home
erste Version am 17.02.2019
letzte Änderung am 20.02.2019
BigData-Spielchen
Ich nehme gerade an einem vierwöchigen Kurs "Big Data Engineer"
teil. Ursprünglich hieß es in der Kursbeschreibung unter Voraussetzungen,
dass Vorkenntnisse mit SQL und Python nötig wären. Mittlerweile
wurde der Text geändert. Statt "Python" steht da jetzt nur noch
"eine Skriptsprache" und "nötig" wurde zu "empfohlen".
Tja.....dumm gelaufen. Für mich zumindest. Der Dozent darf nun
versuchen, alle Teilnehmer auf einen gewissen Mindest-Level zu
bringen. Welch hehres Ziel.
Jedenfalls haben wir in der ersten Woche die SQL-Basics durchgekaut,
in der zweiten Woche kamen redis und MongoDB
an die Reihe. Hadoop und
Spark
wurden schnell noch am Freitag-Nachmittag abgehakt. Zehn volle
Arbeitstage für etwas, das ich mir auch an einem Tag hätte draufschaffen
können..... und es wird nicht besser werden.
Nächste Woche steht dann Python an. Voraussichtlich wirds bei Adam
und Eva losgehen. In der vierten Woche sind zwei Tage für ein
BigData-Projekt reserviert. Jeder der 21 Teilnehmer soll sein
eigenes Projekt machen. Erste Tipps, wo man zu analysierende Daten
finden kann, gab es auch schon: CSV-Dateien mit ein/zwei Megabyte.
Was für ein Trauerspiel.
Nach meinem Verständnis von BigData sollte die Größe der Datenbasis
eher nicht unterhalb der Größe meines CPU-internen Caches
liegen (und auch nicht unter der des RAMs). Daher habe ich mir
vorgestern die gesamten Daten für die Deutschland-Karte von
OpenStreetMap heruntergeladen und werde mal schauen, wie ich damit
herumspielen kann.
Inhaltsverzeichnis
Daten beschaffen und vorverarbeiten
Voranalysen
die Daten in eine Datenbank laden
indizieren der Datenbank
erste Queries
Struktur der Daten
ERMv1.0
Objekte finden
Highscore für Straßennamen
gleichnamige
Straßen auf der OSM-Deutschlandkarte darstellen
der Kurs ist um
Daten beschaffen und vorverarbeiten
Nach der Idee, die OpenStreetMap-Daten für Deutschland zum spielen
zu nutzen, habe ich erstmal im entsprechenden
Wiki gestöbert.
Die Daten gibt es u.A. bei geofabrik.de - oder
konkret hier.
Ich habe natürlich die Version "mit allen Metadatenfeldern" gewählt,
die man allerdings nur bekommt, wenn man einen OSM-Account besitzt. Auch wenn
es bei dieser Version sicher mehr zu analysieren gibt, als bei der
"öffentlichen", könnte der Passus "Es muss sichergestellt werden,
dass damit erstellte Datenbanken und Werke nur
OpenStreetMap-Mitwirkenden zugänglich sind." die Dokumentation
meiner Ergebnisse deutlich aufwendiger werden lassen.
Nach dem Download hatte ich jedenfalls erstmal eine 3.6GB große
Datei germany-latest-internal.osm.pbf
auf der Platte. Die passt zwar nicht mehr in den CPU-Cache, im RAM
würde sie jedoch auch nur etwas über 10% belegen.
Aber: zur Umwandlung in ein Menschen-lesbares Format braucht es laut
Wiki noch osmconvert64.
Das Kommando
dede@i5:/4TB2> ./osmconvert64
germany-latest-internal.osm.pbf
>/2TB/germany-latest-internal.osm.pbf.xml
|
liefert (nach ca. zehn Minuten HDD-Volllast) eine XML-Datei mit
einer Größe von 65GB.
Damit ist die Datenquelle nun immerhin so groß, dass ein Befehl wie
less quasi nur
noch dazu taugt, Anfang und Ende der Datei anzusehen.
Die drei folgenden Kommandos laufen jeweils gefühlte zehn Minuten:
dede@i5:/2TB> wc
germany-latest-internal.osm.pbf.xml
1.000.634.718 4.518.454.918 68.756.258.763
germany-latest-internal.osm.pbf.xml
newline,
word,
byte
dede@i5:~> grep "<node"
/2TB/germany-latest-internal.osm.pbf.xml | wc
297.127.825 2.689.026.860
45.471.325.440
dede@i5:~> grep "</"
/2TB/germany-latest-internal.osm.pbf.xml | wc
60.657.001
60.657.001 500.376.292 |
Immerhin wusste ich danach, dass das XML offenbar eine Milliarde
Zeilen hat. Knapp ein Drittel davon sind vom Typ "Node".
Gut. Das ist jetzt BigData - zumindest auf der mir derzeit zur
Verfügung stehenden Hardware.
Voranalysen
Um nun zukünftig per Python auf die Daten zugreifen zu können, habe
ich noch ein paar Analyse-Jobs laufen lassen.
Zu der Frage, ob ausschließlich doppelte Anführungszeichen genutzt
werden:
dede@i5:/2TB> grep "'"
germany-latest-internal.osm.pbf.xml
<?xml version='1.0' encoding='UTF-8'?>
|
Ergebnis: nur ein Treffer in Zeile 0. Also kommen praktisch keine
einzelnen Anführungszeichen vor. Sehr schön!
Mitten in die Datei schauen geht flott mit dd:
dede@i5:/2TB> dd
if=germany-latest-internal.osm.pbf.xml skip=50056024000
count=10000 bs=1
|
Mit dem skip-Parameter kann man sich vorwärtstasten.
Nach etwas Rumgestöber habe ich mein erstes Python-Script gebaut und
auf die Reise geschickt:
dede@i5:~> ./tagSammler.py
{ 'member': 12.253.942,
'relation': 640.024,
'osm': 1,
'node': 297.127.825,
'way': 48.096.811,
'nd':
398.292.688,
'tag': 183.566.424,
'bounds': 1,
'?xml': 1
}
|
Das Script sucht nach Zeichenfolgen "<" gefolgt von " ". Es zählt
also sowas wie "<node bla blub foo bar>", nicht jedoch sowas
wie "</node>".
Pro gefundener Zeichenfolge zwischen "<" und " " wird je ein
Zähler geführt. Das Ergebnis zeigt die "Häufigkeit pro XML-Tag".
Noch schnell ein Quer-Check:
12.253.942 + 640.024 + 1 + 297.127.825 +
48.096.811 + 398.292.688 + 183.566.424 + 1 + 1 =
939.977.717
1.000.634.718 - 939.977.717 = 60.657.001
|
Fazit: die Summen vom Python-Script passen exakt zu den
grep/wc-Werten. QED
Bezüglich Hierarchie sieht es folgendermaßen aus:
<node
id lat lon version timestamp changeset uid user/>
<node id lat lon version timestamp changeset uid
user>
<tag k v/>
<tag k v/>
</node>
<relation id version timestamp changeset uid user>
<member type ref role/>
<member type ref role/>
<tag k v/>
<tag k v/>
</relation>
<way id version timestamp changeset uid user>
<nd ref/>
<nd ref/>
<tag k v/>
<tag k v/>
</way>
|
die Daten in eine Datenbank laden
Jeder Lauf über die Datei braucht gefühlte zehn Minuten. So kann das
nicht weiter gehen.
Also müssen die Daten etwas abfrage-freundlicher bereitgestellt
werden - will heißen: ich muss sie in eine Datenbank übertragen und
Indices erstellen lassen.
Sinnigerweise pro XML-Tag eine Tabelle. Zusätzlich scheinen mir die
Attribute uid
und user das
Ergebnis einer De-Normalisierung zu sein.
Also braucht es noch eine weitere Tabelle für die Relation userid zu
username.
Der Kode zum Anlegen der Datenbank war schnell fertig. Der
Einfachheit halber habe ich es für (das mir gut bekannte) sqlite3
gebaut:
class Database():
def __init__(self, own_area_code=""):
self.dbname=DATABASENAME
if os.path.exists(self.dbname)==False: # wenn Datenbank-Datei noch nicht existiert -> neu anlegen
self.connection=sqlite3.connect(self.dbname)
#self.connection.text_factory=sqlite3.OptimizedUnicode
cursor=self.connection.cursor()
# id="2078835943" lat="54.8068123" lon="9.5158941" version="2"
# timestamp="2017-04-23T17:19:57Z" changeset="48066661"
# uid="5708153" user="dede67"/>
cursor.execute('CREATE TABLE Nodes' \
' (id INTEGER NOT NULL PRIMARY KEY,' \
' lat REAL,' \
' lon REAL,' \
' version INTEGER,' \
' timestamp INTEGER,' \
' changeset INTEGER,' \
' uid INTEGER)')
cursor.execute('CREATE INDEX Nodes_uid_idx ON Nodes (uid ASC)')
cursor.execute('CREATE TABLE Users' \
' (id INTEGER NOT NULL PRIMARY KEY,' \
' uid INTEGER,' \
' user VARCHAR)') # uid ist temporär (zwecks Test, ob uid im XML unique auf user passt)
cursor.execute("CREATE UNIQUE INDEX nodupe1 ON Users (uid, user)")
# 'k=', 'TMC:cid_58:tabcd_1:Class', ' v=', 'Point'
cursor.execute('CREATE TABLE Tags' \
' (id INTEGER NOT NULL PRIMARY KEY,' \
' k VARCHAR,' \
' v VARCHAR,' \
' node_id INTEGER,' \
' rel_id INTEGER,' \
' way_id INTEGER)')
# 'id=', '1234567', ' version=', '1', ' timestamp=', '2018-08-20T21:57:19Z',
# ' changeset=', '48066661', ' uid=', '5708153', ' user=', 'dede67'
cursor.execute('CREATE TABLE Relations' \
' (id INTEGER NOT NULL PRIMARY KEY,' \
' version INTEGER,' \
' timestamp INTEGER,' \
' changeset INTEGER,' \
' uid INTEGER)')
# 'type=', 'node', ' ref=', '5844791129', ' role=', 'stop'
cursor.execute('CREATE TABLE Members' \
' (id INTEGER NOT NULL PRIMARY KEY,' \
' rel_id INTEGER,' \
' type VARCHAR,' \
' ref INTEGER,' \
' role VARCHAR)')
# 'id=', '123456789', ' version=', '4', ' timestamp=', '2015-03-26T22:16:40Z',
# ' changeset=', '48066661', ' uid=', '5708153', ' user=', 'dede67'
cursor.execute('CREATE TABLE Ways' \
' (id INTEGER NOT NULL PRIMARY KEY,' \
' version INTEGER,' \
' timestamp INTEGER,' \
' changeset INTEGER,' \
' uid INTEGER)')
# 'ref=', '1794045679'
cursor.execute('CREATE TABLE Nds' \
' (id INTEGER NOT NULL PRIMARY KEY,' \
' way_id INTEGER,' \
' ref INTEGER)')
self.connection.commit()
else:
self.connection=sqlite3.connect(self.dbname)
# ###########################################################
#
def __utcStringToTimestamp(self, utc_str):
ts=int(parser.parse(utc_str).timestamp())
#print(ts)
#print(datetime.datetime.utcfromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S'))
return(ts)
# ###########################################################
#
def __insertUser(self, uid, user):
cursor=self.connection.cursor()
try:
cursor.execute('INSERT INTO Users (uid, user) VALUES (?, ?)', (uid, user))
except:
pass
# ###########################################################
#
def insertNode(self, d):
#print((int(d["id"]), float(d["lat"]), float(d["lon"]), int(d["version"]), self.__utcStringToTimestamp(d["timestamp"]), int(d["changeset"]), int(d["uid"])))
cursor=self.connection.cursor()
cursor.execute('INSERT INTO Nodes (id, lat, lon, version, timestamp, changeset, uid)' \
' VALUES (?, ?, ?, ?, ?, ?, ?)',
(int(d["id"]), float(d["lat"]), float(d["lon"]), int(d["version"]), self.__utcStringToTimestamp(d["timestamp"]), int(d["changeset"]), int(d["uid"])))
self.__insertUser(d["uid"], d["user"])
[... u.s.w. ...]
# ###########################################################
#
def commit(self):
self.connection.commit()
BTW: der OSM-User "dede67" bin ich. Folglich braucht sich niemand zu beschweren, dass ich in den Script-Kommentaren die ach so super-geheimen User-Aliasnamen öffentlich mache.
Eine Zeile wird mit folgender Funktion zerlegt: (ich habe mich aus zwei Gründen gegen die Nutzung von lxml entschieden: 1. das XML ist maschinell erstellt und damit sehr sauber bzw. leicht zu parsen und 2. hatte ich keine Lust, ewig und drei Tage danach suchen zu müssen, wie ich lxml dazu bringe, ausschließlich auf einzelnen Zeilen zu operieren....eben weil das komplette XML nicht ins RAM passt)
# ###########################################################
#
def parseLine(ln):
ln=ln.strip()
attrs=[]
cs=""
p1=ln.find("<")
if p1>=0:
p2=ln.find(" ", p1)
if
p2>=0:
# "<tag ...>" oder "<tag .../>" gefunden
tag=ln[p1+1:p2]
attrs=ln[p2+1:].split('"')
cs=attrs.pop()
isClosed=cs=='/>'
elif
ln[p1+1]=="/": #
"</tag>" gefunden
p2=ln.find(">", p1)
tag=ln[p1+2:p2]
isClosed=True
return (tag, fixAttrs(attrs), isClosed)
|
Praktischerweise hat das XML-File nur zwei Ebenen. Das meiste spielt
sich auf der unteren Ebene ab.
Die XML-Tags "tag", "member" und "nd" kommen jedoch grundsätzlich
auf der zweiten Ebene vor und gehören immer zu einem "node",
"relation" oder "way".
Um das abzubilden, werden die XML-Tags erster Ebene nicht in der
selben Zeile geschlossen.
Ohne untergeordnete Informationen sieht ein Node-Tag etwa so aus:
<node id=.. lat=.. lon=.. version=.. timestamp=.. changeset=..
uid=.. user=../>
Mit untergeordnete Informationen hingegen so:
<node id=.. lat=.. lon=.. version=.. timestamp=.. changeset=..
uid=.. user=..>
<tag k=.. v=..>
<tag k=.. v=..>
</node>
Weil parseLine() immer nur auf einer Zeile arbeitet, meldet
es ein nicht beendetes Tag per isClosed an den Aufrufer.
Ärgerlicherweise kommen gelegentlich Node-Sätze vor, bei denen die
User-Information statt als Attribut, als untergeordneter Satz
dargestellt wird.
Etwa so:
<node id=.. lat=.. lon=.. version=.. timestamp=..
changeset=..>
<tag k="created_by"
v="JOSM"/>
Um das abzufangen, wird bei der Aufbereitung der Attribute
gleichzeitig deren Datenstruktur geändert.
Statt als Liste werden die Attribute als defaultdict geliefert:
#
###########################################################
#
def fixAttrs(attrs):
def constant_factory(value):
return lambda: value
attrs_out=collections.defaultdict(constant_factory("0"))
for a in range(0, len(attrs), 2):
attrs_out.update({attrs[a].replace("=", "
").strip():attrs[a+1]})
return attrs_out
|
Damit liefert der Zugriff auf ein attrs["uid"] oder attrs["user"] keinen Fehler mehr,
wenn die ursprüngliche Zeile kein entsprechendes Attribut enthielt.
Nun muss das Script nur noch über die gesamte XML-Datei iterieren,
jede Zeile zerlegen, für Zeilen mit (not isClosed) einen Mini-Stack
verwalten und sämtliche Daten per INSERT-Statement in die Datenbank
übertragen.
Nach ersten Tests war mir klar, dass das Script mehr als 12 Stunden
laufen wird. Um bei Abbrüchen nicht (jedes mal) von vorne beginnen zu
müssen, habe ich noch eingebaut, dass nur alle 100.000 Zeilen ein
COMMIT zur Datenbank geschickt wird. Unmittelbar nach dem COMMIT
wird die aktuelle Datei-Position im XML-File angezeigt.
Dadurch verliert man pro Abbruch (wegen Programm-Fehler oder wegen
Strg-C) maximal 99.999 bereits bearbeitete Zeilen (bzw. eine Minute Rechenzeit).
Beim Neustart des Scripts muss lediglich per seek-Kommando zu der
Stelle hinter dem letzten erfolgreichen COMMIT gesprungen werden.
Und das so zu bauen, war eine wirklich sehr gute Idee! Zunächst konnte ich nämlich das Script, das schon ein paar Stunden gelaufen war, einfach abbrechen und auf einen anderen Rechner umziehen. Dadurch musste mein Hautptechner nicht die Nacht über durchlaufen. Der sog. 11-Watt-PC ist eh immer an und läuft meist zu 99% in der Idle-Loop. Also Strom gespart!
Und am folgenden Vormittag kam es dann natürlich noch, wie es kommen musste.
Ich hatte einen (durch Cut&Paste entstandenen)
Fehler in einem SQL-Statement, das kurz vor Dateiende erstmalig genutzt
wurde.
[.....]
63.1 GB 67735956174
63.1 GB 67777631349
63.2 GB 67818311083
63.2 GB 67858400305
63.2 GB 67898289647
63.3 GB 67938859655
Traceback (most recent call last):
File "./loadOSM.py", line 276, in <module>
db.insertRelation(attrs)
File "./loadOSM.py", line 156, in insertRelation
(int(d["id"]), int(d["version"]),
self.__utcStringToTimestamp(d["timestamp"]),
int(d["changeset"]), int(d["uid"])))
sqlite3.OperationalError: near ")": syntax error
dede@11w:~> ./loadOSM.py
63.4 GB 68069197935
63.5 GB 68213455965
63.6 GB 68336223520
63.7 GB 68439291696
63.8 GB 68534106739
63.9 GB 68639110809
64.0 GB 68754668921
|
Wie gut, dass ich einfach nur die 67938859655 als neue
Startposition eintragen musste, um auch noch das letzte Gigabyte
abarbeiten zu lassen. :-)
indizieren
der Datenbank
Die sqlite3-Datei hatte nach dem Load der Daten eine Größe von 34.7GB. Allerdings gibt es bisher nur Indices auf den Schlüssel-Spalten plus einen "unique index" in der Users-Tabelle, mit dem Duplikate in der uid/user-Relation geblockt werden.
Folgende Indices habe ich einzeln angelegt:
#cursor.execute('CREATE INDEX Nodes_changeset_idx ON Nodes (changeset)') # vorher: 34.7GB, nachher: 39.3GB
#cursor.execute('CREATE INDEX Tags_node_id_idx ON Tags (node_id)') # vorher: 39.3GB, nachher: 41.4GB
#cursor.execute('CREATE INDEX Tags_rel_id_idx ON Tags (rel_id)') # vorher: 41.4GB, nachher: 43.2GB
#cursor.execute('CREATE INDEX Tags_way_id_idx ON Tags (way_id)') # vorher: 43.2GB, nachher: 45.7GB
#cursor.execute('CREATE INDEX Relations_changeset_idx ON Relations (changeset)')
#cursor.execute('CREATE INDEX Relations_uid_idx ON Relations (uid)')
#cursor.execute('CREATE INDEX Members_rel_id_idx ON Members (rel_id)')
#cursor.execute('CREATE INDEX Members_ref_idx ON Members (ref)')
#cursor.execute('CREATE INDEX Ways_changeset_idx ON Ways (changeset)')
#cursor.execute('CREATE INDEX Ways_uid_idx ON Ways (uid)')
#cursor.execute('CREATE INDEX Nds_way_id_idx ON Nds (way_id)') # 53GB
#cursor.execute('CREATE INDEX Nds_ref_idx ON Nds (ref)') # 59.2GB
|
Hinter den Statements steht jeweils das Wachstum der sqlite3-Datei.
Der letzte Index ist zunächst auf einen Fehler gelaufen. Es lag offenbar daran, dass mein Root-Filesystem vollgelaufen war. Weil nach der Fehlermeldung bzw. dem Programmabbruch immer wieder genug freier Platz angezeigt wurde, hat es etwas gedauert, bis ich die Ursache gefunden hatte. Konkret habe ich es erst erkannt, als ich während der Ausführung des CREATE INDEX regelmäßig einen df -h habe laufen lassen.
Nach Löschung einiger Gigabyte unter /var/log/journal/ war mit 27GB wieder genug Platz ... und der Index konnte erfolgreich erstellt werden.
Nun habe ich noch weitere Indices auf den timestamp- und lat/lon-Spalten angelegt.
#cursor.execute('CREATE INDEX Nodes_lat_idx ON Nodes (lat)') # 65GB
#cursor.execute('CREATE INDEX Nodes_lon_idx ON Nodes (lon)') # 70.9GB
#cursor.execute('CREATE INDEX Nodes_timestamp_idx ON Nodes (timestamp)') # 75.6GB
#cursor.execute('CREATE INDEX Relations_timestamp_idx ON Relations (timestamp)')
#cursor.execute('CREATE INDEX Ways_timestamp_idx ON Ways (timestamp)') # 76.2GB
|
Damit sollten jetzt so ziemlich alle relevanten Spalten einen Index haben und künftige Queries hinreichend performant ablaufen.
Nachträglich habe ich auch noch die Spalten members.type, tags.k und tags.v indiziert. Damit hat die DB nun 83.2GB.
erste Queries
select count(*) from nodes where changeset in (select distinct changeset from relations)
29.196.168
select count(*) from nodes where changeset not in (select distinct changeset from relations)
267.931.657
select count(id) from nodes
297.127.825
29.196.168+267.931.657=297.127.825
select count(*) from nodes where changeset in (select distinct changeset from ways)
273.642.231
select count(*) from nodes where changeset not in (select distinct changeset from ways)
23.485.594
273.642.231+23.485.594=297.127.825
select count(*) from nodes where changeset not in (select distinct changeset from ways) and changeset not in (select distinct changeset from relations)
23.185.290
select count(*) from ways where changeset not in (select distinct changeset from nodes) and changeset not in (select distinct changeset from relations)
3.901.498
select count(id) from ways
48.096.811
select count(*) from relations where changeset not in (select distinct changeset from nodes) and changeset not in (select distinct changeset from ways)
104.100
select count(id) from relations
640.024
Alle Queries waren in weniger als einer Minute fertig. Auch passt die Anzahl der Sätze pro Tabelle zu den Werten aus meiner Voranalyse. Soweit ist das ja ganz schön.
Jedoch begreife ich noch nicht, was es mit diesem changeset auf sich hat. Erwartet hatte ich, dass Way- und Relation-Sätze darüber einen Node-Satz referenzieren. Schließlich gibt es lat/lon-Koordinaten nur zum Node....!?
Dieser Query
select changeset from nodes group by changeset having count(*)>1
liefert diverse Sätze und zeigt damit, dass changeset in der Tabelle Nodes non-unique ist.
Und dieser Query
select lat, lon, changeset from nodes where changeset in (select changeset from nodes group by changeset having count(*)>1) order by changeset
hat den SQLite-Manager vollkommen überfordert. Irgendwann ging nur noch kill.
Aus Python heraus abgeschickt, hat er funktioniert ... und gezeigt, dass pro mehrfach vorkommenden changeset diverse unterschiedliche lat/lon-Werte existieren.
Ganz gruselig finde ich, dass der Query
select * from users where uid in (select uid from users group by uid having count(*)>1) order by uid
diverse Sätze liefert. Will heißen: es gibt unterschiedliche Usernamen mit der selben uid.
Wenn ich mir die Daten allerdings genauer ansehe, sind die Usernamen pro uid oft ähnlich. Also wahrscheinlich haben da einige User ihren Usernamen nachträglich geändert. Einzelne kreative Spezialisten scheinen sich sogar bei jeder Änderung einen neuen Namen auszudenken.....
Jedenfalls hilft alles nix....ich muss offensichtlich noch deutlich mehr OSM-Doku suchen, finden und lesen.
Struktur der Daten
Als Einstieg nehme ich mal den Wiki-Eintrag zu OSM XML.
Von da gehts weiter zu Elements und unter "common attributes" findet sich die Bedeutung der Attribute.
Was da bzgl. "id" und "changeset" steht, ist ja schon mal spannend.
Das Attribut "visible" habe ich bei meinen Voranalysen nicht gesehen - ein nachträglicher grep auf das XML-File zeigt aber glücklicherweise keinen einzigen Treffer außerhalb von Strings (will heißen: "visible" wird nicht als Attribut genutzt).
Und zu "user" heißt es "...A user can change their display name at any time...". Das legitimiert immerhin obige Erkenntnis.
Dann fange ich mal mit meinem Haus an. Dazu ermittle ich die Koordinaten südwestlich und nordöstlich von meinem Haus, indem ich in wxOSM auf den entsprechenden Punkten die Funktion "lat/lon to clipboard" wähle. Also:
54.804936379520, 9.524677097797
54.805123435784, 9.525055289268
Der zugehörige Query lautet:
select id, lat, lon, version, changeset from nodes where
lat between 54.804936379520 and 54.805123435784 and
lon between 9.524677097797 and 9.525055289268
Das Ergebnis sind sechs Sätze (die uid lasse ich mal weg...auch wenn in fünf der Sätze meine uid steht).
(4807612352, 54.8050919, 9.5247838, 1, 48003558)
(4026436594, 54.8050213, 9.5247885, 3, 52031838)
(4026436537, 54.8049521, 9.524793, 2, 48003558)
(4807612353, 54.8050964, 9.5249838, 1, 48003558)
(4026436595, 54.8050258, 9.5249897, 2, 48003558)
(4026436539, 54.8049571, 9.5249948, 2, 48003558)
Mal schauen, ob ich deren IDs in einer der anderen Tabellen finde. Also:
select * from <tabelle> where <spalte> in (4807612352, 4026436594, 4026436537, 4807612353, 4026436595, 4026436539)
In "members" gibts weder Treffer in "rel_id" noch in "ref". Auch nicht "nds.id".
Dafür aber in "nds.ref":
(id, way_id, ref)
(314758513, 400006933, 4026436537)
(314758517, 400006933, 4026436537)
(314758514, 400006933, 4026436539)
(314758516, 400006933, 4026436594)
(350521797, 488467015, 4026436594)
(350521801, 488467015, 4026436594)
(314758515, 400006933, 4026436595)
(350521798, 488467015, 4026436595)
(350521800, 488467015, 4807612352)
(350521799, 488467015, 4807612353)
Weiterhin nix in relations.id, tags.id, tags.node_id oder ways.id.
BTW: alle Queries haben in unter drei Sekunden ihr Ergebnis geliefert :-)
Also gibts nur Treffer in "nds". Die hängen unter "ways". Dann suche ich doch mal "nds.way_id" in "ways.id":
select distinct w.id, w.version, w.changeset, datetime(w.timestamp, "unixepoch") from nds n, ways w where w.id=way_id and n.ref in (4807612352, 4026436594, 4026436537, 4807612353, 4026436595, 4026436539)
Liefert (mit DISTINCT):
(400006933, 3, 48008500, '2017-04-21 16:22:09')
(488467015, 3, 52031838, '2017-09-14 09:52:17')
Schon spannend.....zumal meine uid im älteren Satz steht. Welche Wurst hat denn da nach mir noch an meinem Haus rumgepfuscht? ;-)
Die Hausnummer meines Hauses war die allererste Änderung, die ich zu OSM zugefügt habe. Und meine Passwort-Verwaltung zeigt an, dass ich das Passwort für meinen OSM-Account am 21.04.2017 habe generieren lassen. Passt also.
Gleich mal in JOSM gucken..... Auch JOSM kennt für mein Haus nur noch diesen anderen Heini. Das ist ja mal ein starkes Stück.... Quasi ein kapern von Änderungssätzen!?
Aber egal.
An Ways hängen auch Tags. Also:
select * from tags where way_id in (400006933, 488467015)
Ahhh...und endlich finde ich meine Hausnummer:
(155542615, 'addr:city', 'Wees', None, None, 400006933)
(155542616, 'addr:country', 'DE', None, None, 400006933)
(155542617, 'addr:housenumber', '10', None, None, 400006933)
(155542618, 'addr:postcode', '24999', None, None, 400006933)
(155542619, 'addr:street', 'Moorstraße', None, None, 400006933)
(155542620, 'building', 'house', None, None, 400006933)
(166791215, 'addr:city', 'Wees', None, None, 488467015)
(166791216, 'addr:country', 'DE', None, None, 488467015)
(166791217, 'addr:housenumber', '10a', None, None, 488467015)
(166791218, 'addr:postcode', '24999', None, None, 488467015)
(166791219, 'addr:street', 'Moorstraße', None, None, 488467015)
(166791220, 'building', 'house', None, None, 488467015)
Somit geht der Weg von nodes.id zu nds.ref, nds.way_id zu ways.id und dann ways.id zu tags.way_id. Sehr bizarr!?
Immerhin sieht es so aus, dass über ref-Spalten id-Spalten referenziert werden.
Jetzt nehme ich mal eine Straße. Selbes Prinzip wie oben.
Und zwar an einer Stelle, wo die Straße einen Knick macht - wo also ein Punkt in der DB stehen muss.
54.805431071889, 9.524325728416
54.805520734233, 9.524556398392
Der Query:
select id, lat, lon, version, changeset from nodes where lat between 54.805431071889 and 54.805520734233 and lon between 9.524325728416 and 9.524556398392
liefert:
(320269943, 54.8054799, 9.5244139, 2, 14681942)
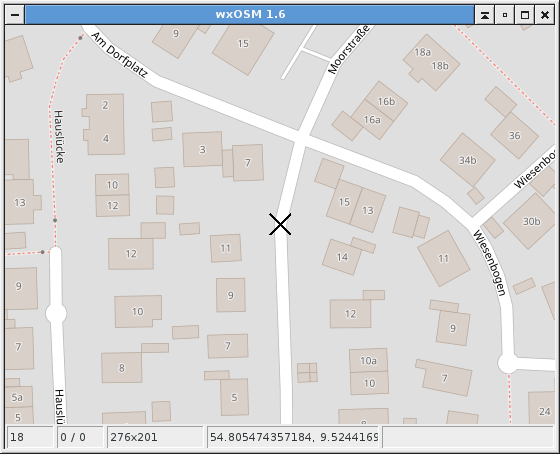
In wxOSM also dieser Punkt:
Jetzt also die (Node) ID 320269943 über alle Tabellen suchen.
select id, way_id, ref from nds where ref=320269943
liefert genau einen Satz:
(17940167, 29115055, 320269943)
Dann
select id, version, datetime(timestamp, "unixepoch"), changeset from ways where id=29115055
liefert:
(29115055, 8, '2014-07-16 18:17:06', 24186869)
Und noch
select id, k, v, node_id, rel_id, way_id from tags where way_id=29115055
liefert:
(45741126, 'name', 'Moorstraße', None, None, 29115055)
(45741127, 'highway', 'residential', None, None, 29115055)
Sehr schön. Morgen werde ich dann schauen, wo und wie ich die anderen Punkte der Straße finde.
Weil ich irgendwie nicht weiter komme, suche ich mal den value "Moorstraße" in "nds":
select count(*) from tags where v="Moorstraße"
liefert:
(1381,)
Das sind mir eigentlich zu viele Treffer. Offenbar gibt es mehrere Moorstraßen in Deutschland.
Vielleicht wäre "Peerekopp" (25 Treffer) erstmal geeigneter, weil die in Deutschland offenbar unique@Wees ist.
In allen 25 Tag-Sätzen mit v="Peerekopp" ist nur die Spalte way_id NOT NULL. Alle 25 Werte in way_id sind unterschiedlich.
Alle Werte von tags.ways_id kommen in ways.id vor.
Ebenfalls kommen alle Werte von tags.ways_id in nds.way_id vor.
Dieser etwas komplexere Query:
select lat, lon, datetime(timestamp, "unixepoch") from nodes where id in
(select distinct ref from nds where way_id in (select distinct way_id from tags where v="Peerekopp"))
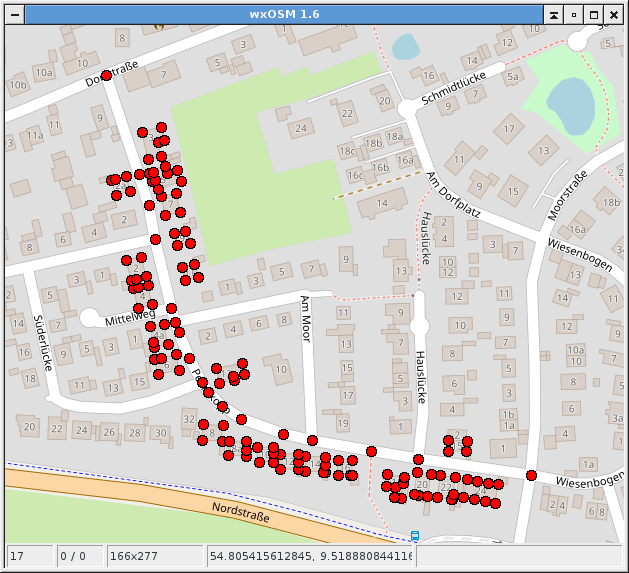
liefert dieses Bild, ...
...wenn ich die lat/lon-Koordinaten in einen GPX-Track schreiben lasse und mir das in wxOSM ansehe.
Offensichtlich sind das alle Nodes, bei denen "Peerekopp" in einem Tag vorkommt. Also auch Gebäude mit ihrer Adresse.
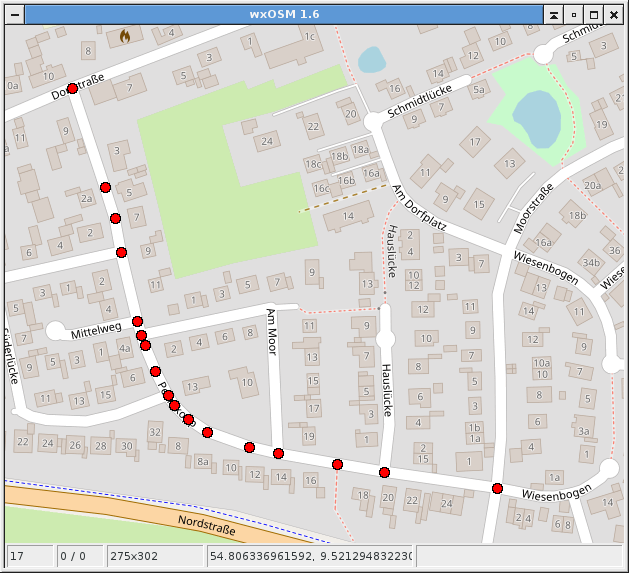
Jetzt habe ich ihn......es braucht noch ein k="name" im Query gegen die Tabelle "tags". Also so:
select lat, lon, datetime(timestamp, "unixepoch") from nodes where id in
(select distinct ref from nds where way_id in (select distinct way_id from tags where k="name" and v="Peerekopp"))
Damit kommt dann endlich das Gesuchte:
Die Fortsetzung folgt auf der nächsten Seite.